使用 EF Core 的 .NET Web API 中的分页


分页允许您检索拆分为页面的大量记录,而不是一次返回所有结果。这在需要检索大量记录的情况下特别有用。在本文中,我将介绍如何使用 Entity Framework Core 在 .NET 8 Web API 中实现偏移和键集分页。
出于演示目的,我创建了一个使用 EF Core 和 MS SQL Server 作为数据库的 .NET 8 Web API 项目。完整的项目可以在文末下载。
演示项目结构
该项目分为三层:
- API 层,其中包含 、 和项目配置,例如依赖注入配置、AutoMapper 配置和 DatabaseSeeder,后者负责在执行应用时向数据库添加数据。ControllersDtos
- 域层,包含类、和 类。ModelsInterfacesService
- 基础结构层,其中包含 和 类。DbContextRepository
分页
分页是将数据拆分为页面的过程,可用于以下场景:不是一次检索所有数据,而是将它们拆分为小铺位并按页检索它们。这样可以提高应用的性能,因为无需一次检索所有数据,并且还允许客户端在数据之间导航。
有两种方法可以实现分页:偏移分页和关键帧分页。每种方法都有优点和缺点,可以在不同的场景中使用,我将介绍这两种方法并演示如何实现它们。
偏移分页
偏移分页需要两个值作为输入:页码和页面大小,它将使用此信息来查询数据。它使用方法(在 SQL 中为 / )返回数据。这种方法支持随机访问分页,这意味着用户可以跳转到他想要的任何页面。在后台,the 指定第一个记录位置,/ 指定要获取的记录数。例如,如果您的数据库包含 500 条记录,并且您请求页码 4 和页大小为 100 的记录,则将返回从位置 301 到 400 的记录:SkipFETCH NEXTOFFSETOFFSETLIMITFETCH NEXT

在下面的代码中,有一个使用 Skip 方法的查询示例(我将在下一主题中更详细地解释它):
var products = await _dbContext.Products.AsNoTracking()
.OrderBy(x => x.Id)
.Skip((pageNumber - 1) * pageSize)
.Take(pageSize)
.ToListAsync();
当页码等于 4 且页面大小等于 100 时发出请求时,EF Core 查询将在以下 SQL 查询中转录(对于 MS SQL Server):
SELECT p.Id, p.Name
FROM Products AS p
ORDER BY p.Id
OFFSET 300 ROWS FETCH NEXT 100 ROWS ONLY
偏移分页的缺点是,如果数据库包含 500 条记录,并且您需要从第 301 行返回到 400 行(即 ),数据库仍必须处理(读取)前 300 个条目(即使它们未返回),因此数据库将浏览 300 行,并跳过这些行以到达第 301 行到 400 行, 这可能会产生巨大的计算负载,该负载会随着跳过的行数而增加。需要跳过的行数越高,对数据库施加的工作负荷就越大。Skip(300).Take(100)
偏移分页的另一个问题是,如果同时发生任何更新,则分页最终可能会跳过某些条目或显示两次。例如,如果在用户从第 2 页移动到第 3 页时删除了某个条目,则整个结果集将“向上移动”,并且将跳过一个条目,或者例如,如果在用户从第 2 页移动到第 3 页时在初始行中添加了一个条目,则最后一个返回的行将再次显示为下一页的第一行。
键集分页
键集分页(也称为_基于搜索_的分页或_光标_分页)是偏移分页的替代方法,它使用子句跳过行,而不是使用偏移分页 ()。在这种方法中,客户端知道最后搜索的元素,并将其用作条件中的筛选器。WHERESkipWhere
键集分页需要两个属性作为输入:引用值(可以是最后一个返回值的某个顺序标识符)和页面大小。
例如,假设引用是上次返回的 Id,并且数据库包含 500 条记录,当您发出引用值等于 300 且页面大小等于 100 的请求时,它将筛选 Id 仅大于 300 的记录,并获取接下来的 100 条记录:

这种分页比偏移分页的性能更高,因为在执行查询时,数据库不需要处理所有前面的行,然后才能达到需要检索的行号。
在下面的代码中,有一个示例使用条件筛选:Wherereference
var products = await _dbContext.Products.AsNoTracking()
.OrderBy(x => x.Id)
.Where(p => p.Id > reference) // in this example, reference is the "lastId"
.Take(pageSize)
.ToListAsync();
当引用值等于 300 且页面大小等于 100 时,EF Core 查询将在以下 SQL 查询中转录(对于 MS SQL Server):
SELECT TOP(100) p.Id, p.Name
FROM Products AS p
WHERE p.Id > 300
ORDER BY p.Id
对于键集分页,键必须是一些可排序的属性,例如顺序 Id 或可以比较的日期时间属性等,在此示例中是该属性。使用该条件时,它不会遍历所有初始行以跳过它们,而是直接跳转到搜索的行。假设索引是在 Id 上定义的,则此查询非常高效,并且对较低 Id 值中发生的任何并发更改也不敏感。IdWhere
与任何其他查询一样,正确的索引对于良好的性能至关重要:确保具有与分页顺序相对应的索引。如果按多个列排序,则可以定义这些多列的索引;这称为复合索引。(Microsoft 文档)
这种分页可以考虑在不需要跳转到随机页面的场景下,而只需要访问上一页和下一页,也可以在想要创建无尽滚动内容应用程序的场景下考虑,因为它高效且解决了偏移分页问题。
键集分页的缺点是它不支持随机访问,用户可以在随机访问中跳转到任何特定页面。此方法适用于用户向前和向后导航的分页界面,这意味着只能执行下一页/上一页导航。
偏移和键集分页 — 优点和缺点
您可以在下面看到一个比较表,其中包含每种方法的优缺点:

对于没有大量数据或需要跳转到特定页面的情况,建议使用偏移分页。考虑到 UI,它可用于呈现数据,不仅可以导航到上一页或下一页,还可以跳转到特定页面。
如果数据量很大,需要确定性能优先级,或者不能遗漏或显示重复的项目,建议使用键集分页。考虑到 UI,它可能非常适合无限滚动的情况,例如在社交媒体上显示帖子等。
偏移分页对象
对于 Offset 分页对象,在 Domain 图层中,我创建了一个 命名 ,其中包含分页属性,例如页码、页面大小、记录总数、总页数(根据总记录数和页面大小计算)以及将包含将返回的数据的通用记录列表的属性:recordPagedResponse<T>
public record PagedResponseOffset<T>
{
public int PageNumber { get; init; }
public int PageSize { get; init; }
public int TotalRecords { get; init; }
public int TotalPages { get; init; }
public List\<T> Data { get; init; }
public PagedResponseOffset(List<T> data, int pageNumber, int pageSize, int totalRecords)
{
Data = data;
PageNumber = pageNumber;
PageSize = pageSize;
TotalRecords = totalRecords;
TotalPages = (int)Math.Ceiling((decimal)totalRecords / (decimal)pageSize);
}
}
请注意,此对象中可能会添加其他属性,例如 HasNextPage、HasPreviousPage 等。
为了检索响应中的数据,我创建了:PagedResponseDto
public record PagedResponseOffsetDto<T>
{
public int PageNumber { get; init; }
public int PageSize { get; init; }
public int TotalPages { get; init; }
public int TotalRecords { get; init; }
public List<T> Data { get; init; }
}
该类使用 AutoMapper 映射到该类:ModelDto
public class PagedResponseProfile : Profile
{
public PagedResponseProfile()
{
CreateMap(typeof(PagedResponse<>), typeof(PagedResponseDto<>));
}
}
以下是分页响应的示例:
{
"pageNumber": 1,
"pageSize": 5,
"totalPages": 20000,
"totalRecords": 100000,
"data": [
{
"name": "Product 1"
},
{
"name": "Product 2"
},
{
"name": "Product 3"
},
{
"name": "Product 4"
},
{
"name": "Product 5"
}
]
}
偏移分页演示
您可以在下面看到 的端点,它返回带有 Offset 分页的产品列表:GETGetWithOffsetPaginationProductsController
[HttpGet("GetWithOffsetPagination")]
[ProducesResponseType(StatusCodes.Status200OK)]
[ProducesResponseType(StatusCodes.Status400BadRequest)]
public async Task<IActionResult> GetWithOffsetPagination(
int pageNumber = 1, int pageSize = 10)
{
if (pageNumber <= 0 || pageSize <= 0)
return BadRequest($"{nameof(pageNumber)} and {nameof(pageSize)} size must be greater than 0.");
var pagedProducts =
await _productService.GetWithOffsetPagination(pageNumber, pageSize);
var pagedProductsDto =
_mapper.Map<PagedResponseOffsetDto<ProductResultDto>>(pagedProducts);
return Ok(pagedProductsDto);
}
此终结点的参数是页码和页面大小。控制器方法调用服务方法:
public async Task<PagedResponse<Order>> GetWithOffsetPagination(
int pageNumber, int pageSize)
{
return await _orderRepository.GetWithOffsetPagination(
pageNumber, pageSize);
}
Service 方法调用 Repository 方法,在其中执行分页查询。在讨论方法本身之前,让我解释一下分页结构。
出于演示目的,我创建了一个非泛型分页方法和一个泛型分页方法。让我们从类中的非泛型开始:ProductRepository
public async Task<PagedResponse<Product>> GetWithOffsetPagination(int pageNumber, int pageSize)
{
var totalRecords = await _dbContext.Products.AsNoTracking().CountAsync();
var products = await _dbContext.Products.AsNoTracking()
.OrderBy(x => x.Id)
.Skip((pageNumber - 1) * pageSize)
.Take(pageSize)
.ToListAsync();
var pagedResponse = new PagedResponse<Product>(products, pageNumber, pageSize, totalRecords);
return pagedResponse;
}
- 在第 3 行,它使用该方法从 Products 中读取数据。DbSetCountAsync
- 在第 5 行到第 9 行,有用于检索数据的 EF Core 查询。
- 在第 6 行,有一个按 ID 对数据进行排序,您可以根据需要对数据进行排序,例如,您可以按产品名称、创建日期等进行排序。OrderBy
- 在第 7 行,该方法用于跳过查询结果中的若干行,由 .该参数指示所需的结果页,并指定每页上的记录数。该公式计算要跳过的记录数才能到达所需的页面。Skip(pageNumber - 1) * pageSizepageNumberpageSize(pageNumber - 1) * pageSize
- 在第 8 行,方法(或在 SQL 中)用于限制查询返回的元素数,以便检索当前页的特定行数。TakeFETCH NEXTLIMIT
- 在第 9 行,结果以List
- 在第 11 行,创建对象PagedResponse
public virtual async Task<PagedResponse<TEntity>> GetWithOffsetPagination(int pageNumber, int pageSize)
{
var totalRecords = await Db.Set<TEntity>().AsNoTracking().CountAsync();
var entities = await Db.Set<TEntity>().AsNoTracking()
.OrderBy(x => x.Id)
.Skip((pageNumber - 1) * pageSize)
.Take(pageSize)
.ToListAsync();
var pagedResponse = new PagedResponse<TEntity>(entities, pageNumber, pageSize, totalRecords);
return pagedResponse;
}
这是此方法的泛型版本,位于以下类中:Repository
如您所见,该方法与非泛型方法非常相似,但不是使用 ,而是使用 。例如,在第 3 行,该方法用于表示 dbContext 中给定类型的列表(在本例中为 )。_dbContext.ProductsDb.Set<TEntity>_dbContext.Set<TEntity>()TEntity
测试偏移分页
为了进行测试,让我们向端点发出请求,在第一页上搜索 5 条记录:GETGetWithOffsetPagination
@PaginationDemo.API\_HostAddress = https://localhost:7220
GET {{PaginationDemo.API_HostAddress}}/api/products/GetWithOffsetPagination?pageNumber=1&pageSize=5
结果如下:
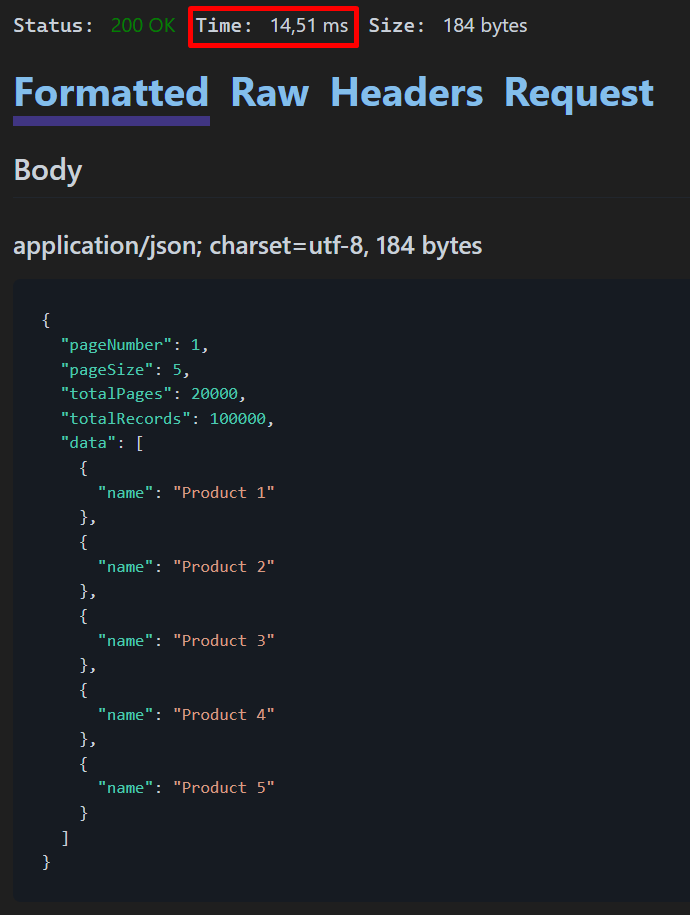
返回了前五条记录,请注意响应时间为 14,51 毫秒。
现在让我们使用页码 20000 提出另一个请求:
@PaginationDemo.API_HostAddress = https://localhost:7220
GET {{PaginationDemo.API_HostAddress}}/api/products/GetWithOffsetPagination/?pageNumber=20000&pageSize=5
回应:
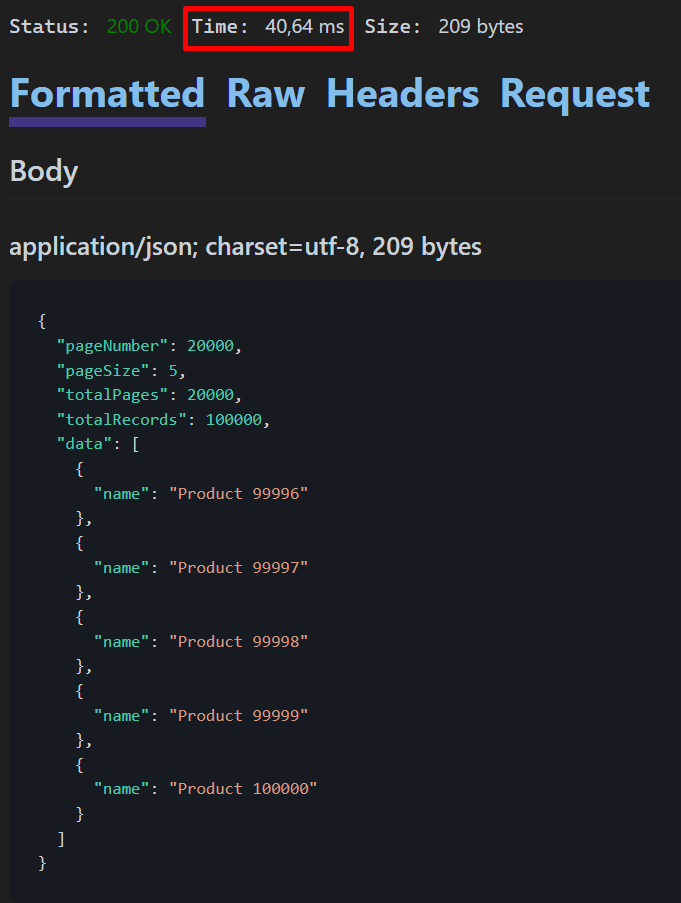
请注意,现在响应时间相当长(40,64 毫秒),这是由于偏移量在数据库中的工作方式。即使我们只返回 5 条记录,数据库也需要处理所有以前的记录。
键集分页对象
对于 Keyset 分页对象,在 Domain 层中,我创建了一个 name,其中包含分页属性,例如引用值(在本例中是最后返回的 Id — 将用作键集)和包含将返回的数据的通用记录列表的属性:record PagedResponseKeyset
public record PagedResponseKeyset<T>
{
public int Reference { get; init; }
public List\<T> Data { get; init; }
public PagedResponseKeyset(List<T> data, int reference)
{
Data = data;
Reference = reference;
}
}
请注意,此对象中可能会添加其他属性,例如 HasNextPage、HasPreviousPage 等。
为了检索响应中的数据,我创建了:PagedResponseKeysetDto
public record PagedResponseKeysetDto<T>
{
public int Reference { get; init; }
public List<T> Data { get; init; }
}
该类使用 AutoMapper 映射到该类:ModelDto
public class PagedResponseKeysetProfile : Profile
{
public PagedResponseKeysetProfile()
{
CreateMap(typeof(PagedResponseKeyset<>), typeof(PagedResponseKeysetDto<>));
}
}
以下是 Keyset 操作的分页响应示例:
{
"reference": 5,
"data": [
{
"name": "Product 1"
},
{
"name": "Product 2"
},
{
"name": "Product 3"
},
{
"name": "Product 4"
},
{
"name": "Product 5"
}
]
}
键集分页演示
您可以在下面看到 的端点,它使用 Keyset 分页返回产品列表:GETGetWithKeysetPaginationProductsController
[HttpGet("GetWithKeysetPagination")]
[ProducesResponseType(StatusCodes.Status200OK)]
[ProducesResponseType(StatusCodes.Status400BadRequest)]
public async Task<IActionResult> GetWithKeysetPagination(
int reference = 0, int pageSize = 10)
{
if (pageSize <= 0)
return BadRequest($"{nameof(pageSize)} size must be greater than 0.");
var pagedProducts =
await _productService.GetWithKeysetPagination(reference, pageSize);
var pagedProductsDto =
_mapper.Map<PagedResponseKeysetDto\<ProductResultDto>>(pagedProducts);
return Ok(pagedProductsDto);
}
此终结点的参数是引用和页面大小。控制器调用服务方法:
public async Task<PagedResponseKeyset<Product>> GetWithKeysetPagination(
int reference, int pageSize)
{
return await _productRepository.GetWithKeysetPagination(
reference, pageSize);
}
Service 方法调用 Repository 方法,在该方法中执行 Keyset 分页。这是类中的方法:GetWithKeysetPaginationCustomerRepository
public async Task<PagedResponseKeyset<Product>> GetWithKeysetPagination(int reference, int pageSize)
{
var products = await _dbContext.Products.AsNoTracking()
.OrderBy(x => x.Id)
.Where(p => p.Id > reference)
.Take(pageSize)
.ToListAsync();
var newReference = products.Count != 0 ? products.Last().Id : 0;
var pagedResponse = new PagedResponseKeyset<Product>(products, newReference);
return pagedResponse;
}
- 在第 3 行到第 7 行中,有用于检索数据的 EF Core 查询。
- 在第 4 行,有一个按 ID 对数据进行排序,您可以根据需要对数据进行排序,例如,您可以按产品名称、创建日期等进行排序。OrderBy
- 在第 5 行,该方法用于筛选引用(在本例中为 )高于上次返回的引用值(在本例中为上次返回的 Id)的记录。请注意,对于键集分页,要搜索的字段需要按顺序排列。WhereId
- 在第 6 行,方法(或在 SQL 中)用于限制查询返回的元素数,以便检索当前页的特定行数。TakeFETCH NEXTLIMIT
- 在第 7 行,结果以 .List
- 在第 9 行,计算要检索的新参考值。
- 在第 11 行,创建对象。PagedResponseKeyset
测试键集分页
为了进行测试,让我们向终结点发出请求以获取前 5 条记录:GETGetWithKeysetPagination
@PaginationDemo.API_HostAddress = https://localhost:7220
GET {{PaginationDemo.API_HostAddress}}/api/products/GetWithKeysetPagination?reference=0&pageSize=5
结果如下:
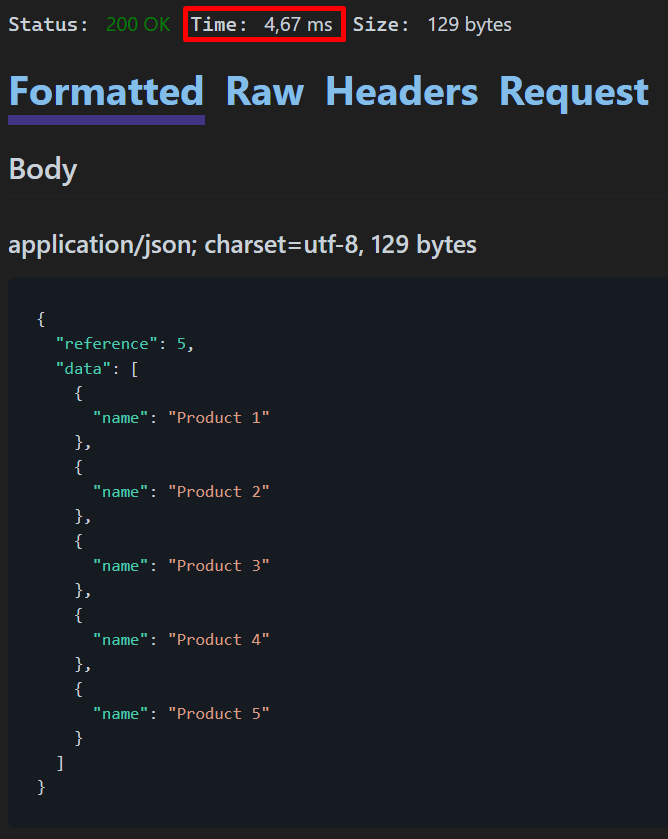
如您所见,与 Offset 分页相比,响应时间已经更快,仅用了 4,67 毫秒。现在让我们测试使用等于 999995 的引用,以返回最后一页:
@PaginationDemo.API_HostAddress = https://localhost:7220
GET {{PaginationDemo.API_HostAddress}}/api/products/GetWithKeysetPagination?reference=99995&pageSize=5
回应:
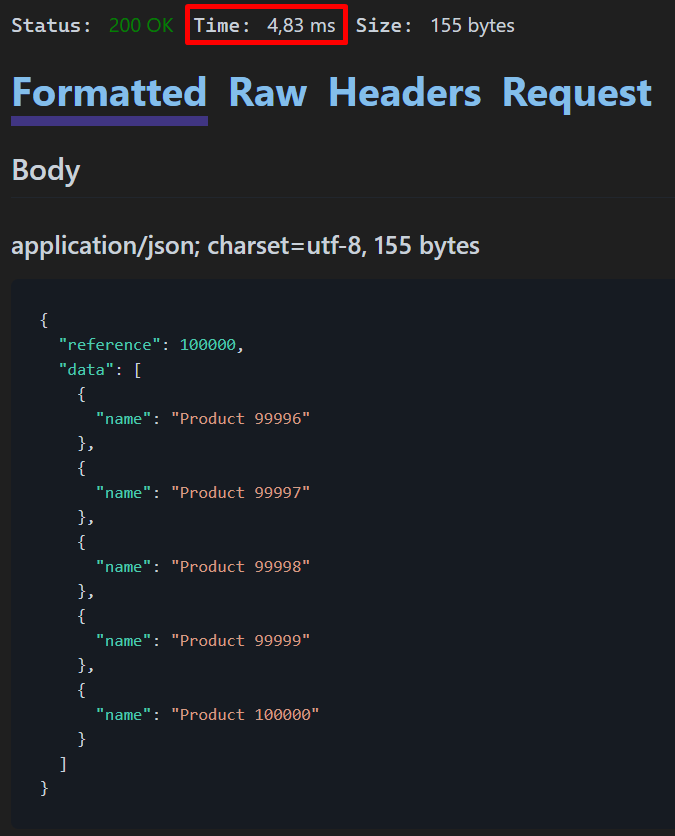
请注意,在这种情况下,响应时间非常短(4,83 毫秒),这是因为键集分页使用条件,这意味着数据库在到达当前行之前不需要处理所有以前的记录。Where
结论
分页允许您检索拆分为页面的数据,这是在有大量记录的情况下检索数据的好方法。它通过减少需要一次加载的数据数量来提高网站性能,并且还通过提供一种在大量数据之间导航的简单方法来增强用户体验。当需要跳转到特定页面时,可以使用偏移分页,当跳转到特定页面不是必需且需要优先考虑数据一致性或性能时,可以使用键集分页。
源代码获取:公众号回复消息【code:14077】

 code:14077 获取下载地址
code:14077 获取下载地址