使用 ValueTask 异步操作的节省内存

在现代 C# 编程中,了解异步构造(如 和 )之间的细微差别对于优化内存使用率和应用程序性能至关重要。这个故事深入探讨了一个真实世界的场景,在这个场景中,使用可以节省大量内存。通过实际用例和基准分析,我们探讨了如何有效地处理异步操作,同时最大限度地减少内存分配。ValueTaskTaskValueTaskValueTask
- 大多数时候可能不会击中。await
- 大多数情况下,您将立即可用的结果,因此该方法将同步完成。await
实际使用案例
在下面的示例中,我们将研究第一个用例,我们将在其中说明什么是以及我们如何从中受益。这个用例是大多数开发人员现在可能在他们的代码中拥有的东西,并且应用该构造,我们将节省相当大的内存分配块。那是因为工作方式与 .让我们尝试通过查看代码示例来解释它们的不同之处。ValueTaskValueTaskValueTaskTask
假设我们有一个名为 .这是一项服务,您可以在其中传入 GitHub 用户名,并调用公共 GitHub API 以获取有关该特定用户的信息。一旦它进行调用以获取用户信息,它就会将其缓存在内存中一个小时,就像我们在下面的代码示例中看到的那样:GitHubService
public class GitHubService
{
private readonly IMemoryCache _cachedGitHubUserInfo = new MemoryCache(new MemoryCacheOptions());
private static readonly HttpClient HttpClient = new()
{
BaseAddress = new Uri("https://api.github.com/"),
};
static GitHubService()
{
HttpClient.DefaultRequestHeaders.Add(HeaderNames.Accept, "application/vnd.github.v3+json");
HttpClient.DefaultRequestHeaders.Add(HeaderNames.UserAgent, $"Medium-Story-{Environment.MachineName}");
}
public async Task<GitHubUserInfo?> GetGitHubUserInfoAsyncTask(string username)
{
var cacheKey = ("github-", username);
var gitHubUserInfo = _cachedGitHubUserInfo.Get\<GitHubUserInfo>(cacheKey);
if (gitHubUserInfo is null)
{
var response = await HttpClient.GetAsync($"/users/{username}");
if (response.StatusCode == HttpStatusCode.OK)
{
gitHubUserInfo = await response.Content.ReadFromJsonAsync<GitHubUserInfo>();
_cachedGitHubUserInfo.Set(cacheKey, gitHubUserInfo, TimeSpan.FromHours(1));
}
}
return gitHubUserInfo;
}
}
最后,它返回一个对象,其中包含 GitHub 用户的 、 、 和 的 :usernameprofileUrlnamecompanyrecordGitHubUserInfo
public record GitHubUserInfo([property: JsonPropertyName("login")] string Username,
[property: JsonPropertyName("html_url")] string ProfileUrl,
[property: JsonPropertyName("name")] string Name,
[property: JsonPropertyName("company")] string Company);
假设这是一个更大的CRM系统的一部分,您可以在其中保存有关客户的信息,在我们的案例中,这些客户恰好是开发人员。
在许多用例中,您可以有效地从外部第三方 API 或其他服务或数据库获取某些内容,将其缓存在内存中,然后在应用程序中对其进行某些操作。而且,与往常一样,我们应该尝试使用一种方法 ,因为调用 API 是一个 I/O 操作,我们不希望在这里对我们的线程进行阻塞操作
这里的问题是,我们返回一个 ,而 a 是将在堆上分配的引用类型。如果我们更仔细地考虑一下,在我们的示例中,我们只需要每小时返回一次特定的 GitHub 用户名,而其他所有时间我们只需要返回我们保存在内存缓存中的用户信息。TaskTaskTask
ValueTask 来救援
这就是发挥作用的地方。此示例是目前在代码中用于节省内存的最简单方法之一。 实际上是一种有区别的并集,可以是以下两种情况之一:a(即某种类型)或 .这意味着我们可以将返回类型替换为 a 并获得一些内存分配,因为只有当我们的方法实际需要返回 .ValueTaskValueTaskValueTaskTTask<T>Task<T>ValueTask<T>TaskTask
在所有其他时候,我们从内存缓存中取回用户信息,我们不需要分配任何宝贵的内存。因此,如果我们想配置相同的方法来返回 a 而不是 ,我们可以通过引入一个名为 inside 的新方法来编写它,正如我们在下面的代码片段中看到的那样:GetGitHubUserInfoAsyncTaskValueTask<GitHubUserInfo>Task<GitHubUserInfo>GetGitHubUserInfoAsyncValueTaskGitHubService
public async ValueTask<GitHubUserInfo?> GetGitHubUserInfoAsyncValueTask(string username)
{
var cacheKey = ("github-", username);
var gitHubUserInfo = _cachedGitHubUserInfo.Get<GitHubUserInfo>(cacheKey);
if (gitHubUserInfo is null)
{
var response = await HttpClient.GetAsync($"/users/{username}");
if (response.StatusCode == HttpStatusCode.OK)
{
gitHubUserInfo = await response.Content.ReadFromJsonAsync\<GitHubUserInfo>();
_cachedGitHubUserInfo.Set(cacheKey, gitHubUserInfo, TimeSpan.FromHours(1));
}
}
return gitHubUserInfo;
}
基准分析:与 ValueTask 性能评估Task
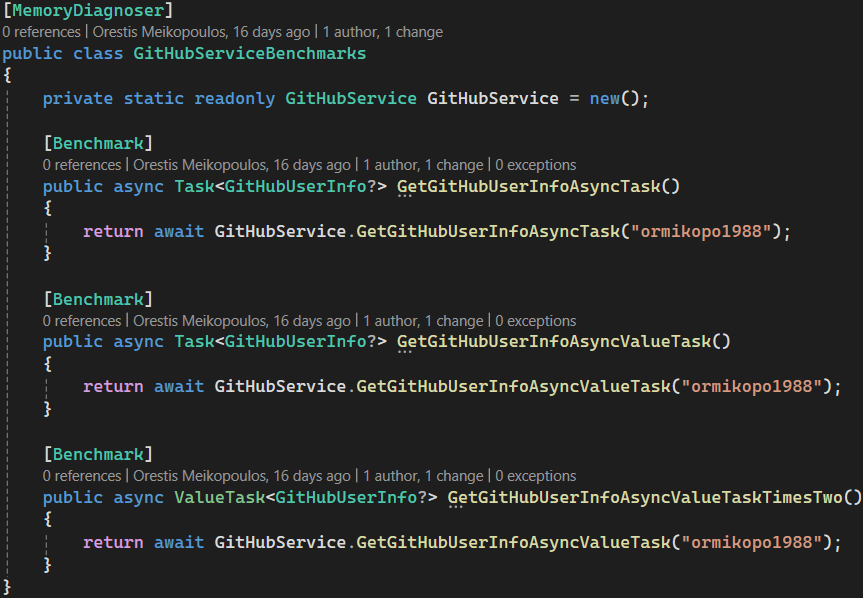
让我们尝试通过运行基准测试来了解 和 返回类型之间的区别。为此,我们将使用 BenchmarkDotNet 库。首先,我们创建一个名为的类,并用属性装饰它。这意味着,每当我们运行这些基准测试时,我们都会得到实际为它们分配的内存量:Task<T>ValueTask<T>GitHubServiceBenchmarksMemoryDiagnoser
[MemoryDiagnoser]
public class GitHubServiceBenchmarks
{
private static readonly GitHubService GitHubService = new();
[Benchmark]
public async Task<GitHubUserInfo?> GetGitHubUserInfoAsyncTask()
{
return await GitHubService.GetGitHubUserInfoAsyncTask("ormikopo1988");
}
}
在我们的第一个基准测试中(上面的细节),我们有一个任务,我们只返回某种类型的,在本例中为 。TaskGitHubUserInfo
注意:请记住在运行基准测试之前将控制台应用的 Configuration Manager 更改为“发布”模式。
在第一次执行期间,对于特定请求的 GitHub 用户名,我们的缓存将为空,因此我们将调用 GitHub API。在得到响应后,我们立即将其缓存 1 小时,遵循所谓的缓存端模式。之后,在接下来的 1 小时内,对同一 GitHub 用户名的所有其他调用都将从内存中获取对象,这几乎是我们在典型系统中可能遇到的情况,只要此信息不经常更改并且我们希望将其缓存在某个地方。GitHubUserInfo
var cacheKey = ("github-", username);
var gitHubUserInfo = _cachedGitHubUserInfo.Get<GitHubUserInfo>(cacheKey);
if (gitHubUserInfo is null)
{
var response = await HttpClient.GetAsync($"/users/{username}");
if (response.StatusCode == HttpStatusCode.OK)
{
gitHubUserInfo = await response.Content.ReadFromJsonAsync<GitHubUserInfo>();
_cachedGitHubUserInfo.Set(cacheKey, gitHubUserInfo, TimeSpan.FromHours(1));
}
}
return gitHubUserInfo;
现在让我们添加第二个基准测试,在这个基准测试中,我们将调用该方法,而不是 ,返回 :GetGitHubUserInfoAsyncValueTaskTaskValueTaskGitHubUserInfo
[Benchmark]
public async Task<GitHubUserInfo?> GetGitHubUserInfoAsyncValueTask()
{
return await GitHubService.GetGitHubUserInfoAsyncValueTask("ormikopo1988");
}
首先,让我们试着明确表示,我们不希望看到速度上的任何差异。这里重要的是内存,我们投入垃圾回收器的工作量以及我们在堆上分配的内存。
如果我们运行这个基准测试并等到它完成,看看结果是什么样子的,我们可能会看到它更快一些,但如果我们再次运行测试,可能会更快一些。因此,为了简单起见,就速度而言,我们将假设两个示例是相同的:TaskValueTask

基准测试结果
需要注意的有趣事情是,垃圾回收和分配的内存少了 72 个字节。但是你可能会问,72 字节真的重要吗?好吧,如果我们考虑一下,它不仅总共有 72 个字节。每次我们调用该特定方法时,以及每次有该方法的任何其他调用方也返回 .Gen0Task
但这究竟意味着什么?因为使用 ,所以在第二个基准测试中,即使该方法实际上返回 .这意味着我们可能没有充分利用这里的优势,因为基准测试方法也可以使用这种性能改进。ValueTaskTaskTaskGetGitHubUserInfoAsyncValueTaskGitHubServiceValueTaskValueTask
实际上,让我们创建第三个基准测试方法,该方法也将返回 a 而不是 ,并且仍然从以下位置调用相同的方法:GetGitHubUserInfoAsyncValueTaskTimesTwoValueTaskTaskGetGitHubUserInfoAsyncValueTaskGitHubService
[Benchmark]
public async ValueTask<GitHubUserInfo?> GetGitHubUserInfoAsyncValueTaskTimesTwo()
{
return await GitHubService.GetGitHubUserInfoAsyncValueTask("ormikopo1988");
}
请注意,我们将在这里看到的结果仅适用于父方法也可以从使用 中受益的情况,这意味着它不会调用任何与 I/O 相关的内容。如果确实如此,那么内存会更低,因为我们也将保存第二个分配,这会产生连锁效应。我们只想切断链条,然后我们可以继续使用一个。ValueTaskTaskTask
非常重要的一点是,一旦我们等待一个,我们就不想再次附加它。这与 A 的工作方式完全不同 。我们也不想有一个 像 or 这样的结构 ,并以任何身份以大规模的方式等待它们。基本上,一旦我们用一个做某事,我们需要保持原样。ValueTaskTaskValueTaskTask.WhenAllTask.WaitAllValueTask
回到我们的例子,正如我们在第三个基准测试中看到的那样,我们又节省了 72 个字节,因为我们也节省了第二个分配:

基准测试结果
因此,如果我们每秒有 1000 个请求,并且我们设法将这种技术用于其中的 50 或 100 个,我们将节省相当多的内存。我们研究的用例很常见,也是对该类型的最安全的介绍。还有一些不那么简单的地方,我们也可以利用它来发挥我们的优势,但这超出了本文的范围。
最后,请始终记住,正如我们上面已经提到的,有一些注意事项。例如,如果我们有一个 ,并且我们等待它,那么我们真的不应该重新等待它。我们不能将其保留为内存并继续等待它(例如,出于初始化目的)。如果我们小心这些事情,那么我们应该没事。
那么我们应该到处使用吗?好吧,根据经验,如果我们有一些代码,就像我们之前检查过的代码一样,我们有某种缓存或某种机制,可以防止我们的代码大多数时候进入方法的 I/O 部分,那么我们可以使用并获得分配中的这些性能改进。这一点很重要,尤其是在高度可扩展和高吞吐量的应用程序中,每个额外的内存分配都非常重要。ValueTaskValueTask
但是,一般来说,我们不希望在代码中从一开始就使用 a,除非我们真的知道自己在做什么。基本上,我们应该始终以 .如果我们开始发现这些性能下降或性能瓶颈,并且我们想在内存分配方面优化我们的应用程序,并且我们处于一个示例的上下文中,就像我们在当前故事中展示的那样,那么这是一个很好且安全的起点,始终牢记注意事项。
通过实际示例和基准分析,这个故事展示了过渡到如何显著减少内存分配,尤其是在缓存结果普遍存在的情况下。虽然提供了令人信服的好处,但考虑到它的细微差别,明智地使用它至关重要。通过有选择地集成,开发人员可以释放性能提升,尤其是在高吞吐量应用中。