.net中的EF比你想象的更智能

尽管 EF 很受欢迎,但开发人员还是懒得阅读文档😬。结果,出现了大量额外的和大多数时候的冗余代码。
在今天的文章中,我们将探讨常见的代码示例和改进它们的方法。你将了解如何使实体框架 (EF) 代码更简洁。此外,我们将介绍一些您可以与朋友😉分享和讨论的高级技术。
事不宜迟,让我们开始吧
Domain
在下面的所有示例中,将使用以下实体:
public class User
{
public int Id { get; set; }
public string Name { get; set; }
public ICollection\<Address> Addresses { get; set; }
}
public class Address
{
public int Id { get; set; }
public string Name { get; set; }
public int UserId { get; set; }
}
No need in DbSet
每个使用 EF 的人都知道,您需要在 .这样,Entity Framework 将在数据库中创建表,并将它们与相应的属性进行匹配。
public class ApplicationDbContext : DbContext
{
public DbSet<User> Users { get; set; }
public DbSet<Address> Addresses { get; set; }
}
但是,您实际上并不需要这样做。只要配置了实体并在 EF 中注册了配置,就可以确定应创建哪些表:DbContext
public class ApplicationDbContext : DbContext
{
// public DbSet<User> Users { get; set; }
// public DbSet<Address> Addresses { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// search for all FLuentApi configurations
// modelBuilder.ApplyConfigurationsFromAssembly(typeof(ApplicationDbContext));
modelBuilder.Entity<User>();
modelBuilder.Entity<Address>();
}
}
稍后可以通过以下方法访问该表:
await using var dbContext = new ApplicationDbContext();
dbContext.Set<User>().AddAsync(new User());
. . .
当您想要限制对某些表的直接访问(这在 DDD 中很常见)或实现泛型操作时,这非常有用。DbContext
更新子项的集合
通常,UI 允许同时更改多个实体。更新父实体及其所有子实体是一项常见任务。例如,在下图中,我们可以更改用户名并在单个页面上添加/更新/删除其地址。
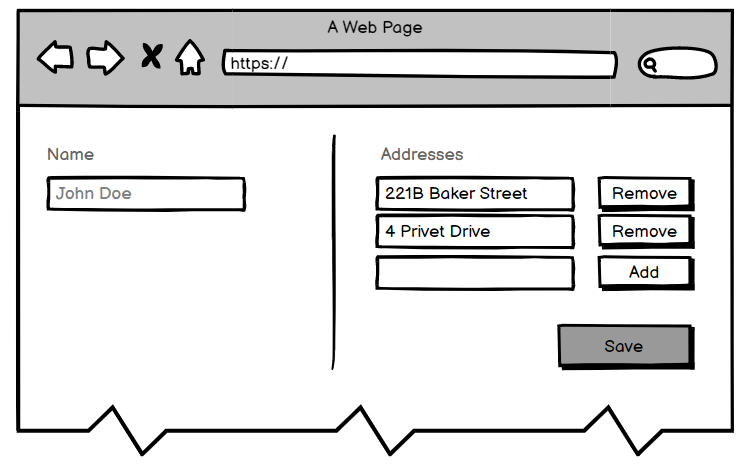
尽管这似乎不是最复杂的事情,但在实践中,它让许多开发人员摸不着头脑。
这里只是我所看到的代码的一个近似示例(请不要试图理解它,只需快速浏览一下):
using (var dbContext = new AppDbContext())
{
// Retrieve the user and its addresses from the database
var user = dbContext.Users.Include(u => u.Addresses).Find(userId);
// Update the user's name
user.Name = newName;
// Add/Update/Delete addresses
var existingAddressNames = user.Addresses.Select(a => a.Name);
var addressesToDelete = existingAddressNames.Except(newAddressNames).ToList();
var addressesToAdd = newAddressNames.Except(existingAddressNames).ToList();
// Remove addresses that are no longer in the updated list
foreach (var addressName in addressesToDelete)
{
var addressToDelete = user.Addresses.FirstOrDefault(a => a.Name == addressName);
if (addressToDelete != null)
{
user.Addresses.Remove(addressToDelete);
dbContext.Addresses.Remove(addressToDelete);
}
}
// Add new addresses
foreach (var addressName in addressesToAdd)
{
var newAddress = new Address { Name = addressName };
user.Addresses.Add(newAddress);
dbContext.Addresses.Add(newAddress);
}
// Update addresses
. . .
// Save changes to the database
dbContext.SaveChanges();
}
它可以通过大量使用 Linq 和其他类型的重构来优化。我很确定也有一些错误。但我的观点是,这是相当多的工作。你可以通过观察它有多大来意识到这一点。该代码将变得更大,您拥有的实体越多。
一个更简单的方法是删除所有地址并重新填充它们:
using (var dbContext = new AppDbContext())
{
// Retrieve the user and its addresses from the database
var user = dbContext.Users.Include(u => u.Addresses).Find(userId);
// Update the user's name
user.Name = newName;
// Update addresses
user.Addresses.Clear();
user.Addresses.Add(new Address
{
Id = 2, // this one has an Id and need to be updated
Name = "Rename Existing",
});
user.Addresses.Add(new Address
{
Name = "Add New",
});
// Save changes to the database
dbContext.SaveChanges();
}
我希望 EF 删除所有用户的地址并插入新🤔地址。然而,事实并非如此。
让我们检查生成的 SQL:
DELETE
FROM [Address]
WHERE [Id] = 1;
UPDATE [Address]
SET [Name] = 'Rename Existing'
WHERE [Id] = 2;
INSERT INTO [Address] ([Name], [UserId])
VALUES ('Add New', 1);
更新子实体从未如此简单 😱
我们不必编写任何复杂的算法来计算添加哪些实体、更新了哪些实体以及删除了哪些实体。Ef 足够聪明,可以自己完成,谢天谢地 Change Tracker 😏 .
从其他范围访问更改
好了,这次要了解问题所在,我希望你实际分析一下代码,不过别担心,我会帮助你的 🙂
想象一下,我们将注册为 .我们还有两个服务和.它们都对同一个用户实体进行操作,并且都尝试更新相同的属性。我们假设原始用户的名字是 John。现在乐趣开始了:
- 您可以在注释 No1 中看到,我们正在将用户重命名为 Joe,但更改尚未提交到数据库。然后被调用。它还会从数据库加载同一用户并更新其名称。你能说出用户的名字吗?是还是?_nameService.UpdateUserName()question 1“John”“Joe”
- 另请注意,在注释 No2 中,我们将用户重命名为 Jonathan,但是,这次被调用。您能说出当我们返回到原始代码时名称字段中的值吗?是还是?
class UserService
{
public void UpdateUser([FromServices] AppDbContext dbContext)
{
var user = dbContext.Users.First(u => u.Id == 1);
user.Name; // John
user.Name = "Joe"; // 1
_nameService.UpdateUserName();
user.Name; // question 2 ???
dbContext.SaveChanges();
}
}
class NameService
{
public void UpdateUserName([FromServices] AppDbContext dbContext)
{
var user= _dbContext.Users.First(p => p.Id == 1);
user.Name; // question 1 ???
user.Name = "Jonathan"; // 2
dbContext.SaveChanges();
}
}
如果我是一个不知道 EF 如何工作的人,我会猜测第一种情况和第二种情况。毕竟,这就是可变范围的工作方式。但是,在这种情况下,EF 更智能。以下是实际结果:
class UserService
{
public void UpdateUser([FromServices] AppDbContext dbContext)
{
var user = dbContext.Users.First(u => u.Id == 1);
user.Name; // John
user.Name = "Joe"; // 1
_nameService.UpdateUserName();
user.Name; // Jonathan
user.Name = "Here's Johnny";
dbContext.SaveChanges();
}
}
class NameService
{
public void UpdateUserName([FromServices] AppDbContext dbContext)
{
var user= dbContext.Users.First(p => p.Id == 1);
user.Name; // Joe
user.Name = "Jonathan"; // 2
dbContext.SaveChanges();
}
}
即使实体在另一个服务中重新加载,我们仍然可以访问其他代码所做的更改。发生这种情况是因为它实际上不是一个新实体。
由于更改跟踪器,EF 会提取实体,检查其主键,并查看已跟踪的实体,因此返回已跟踪的实体。因此,在一个作用域中对实体所做的所有更改都存在于另一个作用域中。
这既有利也有弊。一方面,我们可以确定与我们合作的实体始终是最新的,无论通过其他方法进行何种操作。另一方面,我们可能会意外地提交我们不知道的更改。
Find() 与 First()
这是另一个例子。
我们有一个方法,可以加载一个用户并更新其名称,然后加载同一个用户并更新其地址。
class UserService
{
public void UpdateUser(int userId, string userName, List<Address> addresses)
{
UpdateName(userId, userName);
UpdateAddresses(userId, addresses);
}
private void UpdateName(int userId, string userName)
{
var user = _dbContext
.Users
.First(u => u.Id == userId);
user.Name = userName;
_dbContext.SaveChanges();
}
private void UpdateAddresses(int userId, List<Address> addresses)
{
var user = _dbContext
.Users
.Include(u => u.Addresses)
.First(u => u.Id == userId);
user.Addresses = addresses;
_dbContext.SaveChanges();
}
}
您可以看到从数据库中提取了两次相同的用户。正如我们已经知道的,在这两种情况下,实体框架都将返回相同的实体。但是,仍然存在一个问题,即使已经跟踪了用户,它也会创建两个请求。我想 EF 毕竟😒没那么聪明SELECT
当然,我们可以有另一种方法来加载用户,然后在 和 中使用它。但是,还有另一种解决方案。
为避免两次获取用户,您可以使用代替 。
Find()按主键从数据库中返回实体。这是第一次向数据库发出请求。然后跟踪该实体,对于所有将来的调用,该实体将立即返回到缓存中。
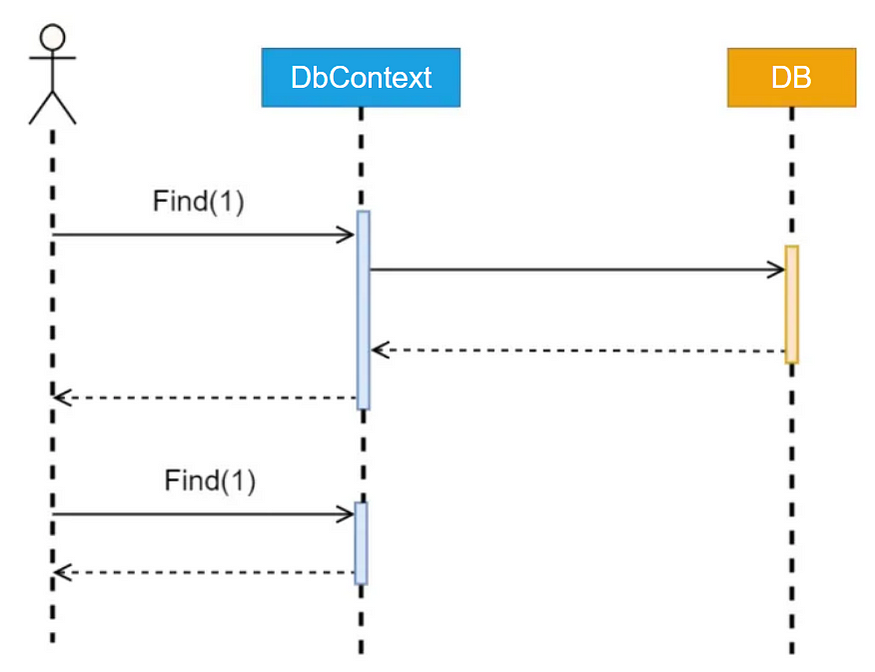
它以这种方式工作,因为 是 EF 中的实际方法,并且 EF 的开发人员可以直接访问更改跟踪器。相比之下,它只是在任何字段(不一定是主键)上带有谓词的扩展方法。
abstract class DbSet<TEntity>
{
. . .
public Task FindAsync(params object[] primaryKey);
. . .
}
使用 TransactionScope 还原更改
经常发生的情况是,您的业务逻辑不仅仅是更新某些字段。您可以经常更新一些属性,执行一些计算,然后再更新模型的其余部分。想象一下,在计算过程中出了什么问题:
class UserService
{
public void UpdateUser(int userId, string userName, List<Address> addresses)
{
UpdateName(userId, userName);
// some business logic that can do this:
// throw new BusinessLogicException(💥)
UpdateAddresses(userId, addresses);
}
private void UpdateName(int userId, string userName)
{
var user = _dbContext
.Users
.Find(userId);
user.Name = userName;
_dbContext.SaveChanges();
}
private void UpdateAddresses(int userId, List<Address> addresses)
{
var user = _dbContext
.Users
.Include(u => u.Addresses)
.Find(userId);
user.Addresses = addresses;
_dbContext.SaveChanges();
}
}
这意味着有些数据被保存,而有些则没有。这会导致数据不一致。
当然,我们可以在这里和那里添加一些,编写补偿操作,使我们的代码变得复杂,等等。但是我们为什么要这样做🤔呢?try/catches
使用 EF,只需几行即可使用:
class UserService
{
public void UpdateUser(int userId, string userName, List<Address> addresses)
{
using (var transaction = db.Database.BeginTransaction())
{
UpdateName(userId, userName);
throw new BusinessLogicException(💥)
UpdateAddresses(userId);
transaction.Commit();
}
}
. . .
}
EF 创建一个新事务并将其提交到 .但是,如果它看到已经有一个正在进行的事务,它将附加所有更改。
这次不会有任何数据不一致。 可以随心所欲地调用,数据在点击之前不会被保存。
Linq 链接
还有最后一个。我看到我的同事写了这样的复杂查询:
var result = _dbContext
.Users
.Where(u => u.Name.Contains("J") && u.Addresses.Count > 1 && u.Addresses.Count < 10) &&
(idToSearch == null || u.Id == idToSearch)
.ToList();
他试图将所有条件放在单个语句中:.Where()
所以,我建议这样重写:
var query = _dbContext
.Users
.Where(u => u.Name.Contains("J"))
.Where(u => u.Addresses.Count > 1 && u.Addresses.Count < 10);
if (idToSearch is not null)
{
query = query
.Where(u.Id == idToSearch);
}
var result = query
.ToList();
理由如下:
- 将条件拆分为单独的子句可使代码更具可读性,尤其是在处理复杂条件或长表达式时Where
- 它的格式更好,允许开发人员单独关注每个过滤器
- 每个条件都是分开的,因此更容易理解每个过滤器的意图
- 使用单独的子句,您可以独立重用或修改条件。如果需要更改其中一个条件,可以在不影响其他条件的情况下进行更改。它在维护或改进代码时提供了更大的灵活性Where
- 更改为特定条件,会更好地显示在 git 等版本控制系统中,使 PR 审核过程窒息
他同意我的看法,但拒绝这样做,因为这会降低性能。起初我很困惑。这怎么可能🤔?直到那时我才意识到,他想到了那些 Linq 运算符,因为它们是针对常规集合执行的。
EF 不会按名称筛选行,而是按地址筛选剩余行,依此类推。它会将这些筛选器运算符转换为 **SQL。**从技术上讲,您使用哪种方法并不重要。
我还建议将这种方法也用于常规集合,因为:
- 代码库是一致的
- 大多数时候,在内存集合中,我们正在处理的内存集合很小
- 这两种方法之间的性能差异可以忽略不计,因为即使是常规的 Linq 也无法以这种方式工作,但这是另一回事🙃
结论
事实证明,EF 是一个强大的工具,它提供了比眼睛看到的更多的功能。通过有效利用其功能,开发人员可以简化复杂的任务、优化性能并确保数据一致性。
了解 EF 的内部工作原理使我们能够释放其全部潜力并简化我们的代码,使开发过程更顺畅、更高效。