ZLinq 革命性发布:零分配、高性能、全兼容的 LINQ 终极形态!
上个月发布了 ZLinq v1!通过基于结构体(struct)和泛型的构建,它实现了零内存分配(zero allocations)。它包含多种扩展,如 LINQ to Span、LINQ to SIMD、LINQ to Tree(文件系统、JSON、GameObject 等)、一个用于任意类型的开箱即用(Drop-in)替代源代码生成器(Source Generator),并支持包括 .NET Standard 2.0、Unity 和 Godot 在内的多个平台。目前它在 GitHub 上已超过 2000 星。
https://github.com/Cysharp/ZLinq
基于结构体的 LINQ 本身并不罕见,多年来许多实现都尝试过这种方法。然而,直到现在,还没有一个真正实用的方案。它们通常遭受极端程序集大小膨胀、操作符覆盖不足或由于优化不足导致的性能问题,从未超越实验状态。借助 ZLinq,我们旨在创建一个实用的解决方案,通过 100% 覆盖 .NET 10 中的所有方法和重载(包括新方法如 Shuffle, RightJoin, LeftJoin),确保 99% 的行为兼容性,并实施超越仅减少分配的优化,包括 SIMD 支持,从而在大多数场景中表现更优。
这得益于我在实现 LINQ 方面的丰富经验。2009 年 4 月,我发布了 linq.js,一个用于 JavaScript 的 LINQ to Objects 库(令人欣喜的是 linq.js 现在仍由 fork 它的人维护着!)。我还为 Unity 实现了广泛使用的 Reactive Extensions 库 UniRx,并最近发布了它的演进版 R3。我还创建了诸如 LINQ to GameObject、LINQ to BigQuery 和 SimdLinq 等变体。通过将这些经验与零分配相关库(ZString, ZLogger)和高性能序列化器(MessagePack-CSharp, MemoryPack)的知识相结合,我们实现了创建优于标准库替代品的雄心目标。
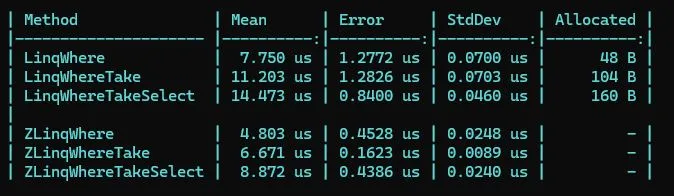
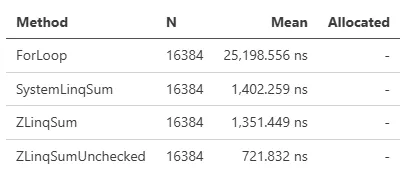
这个简单的基准测试表明,当链式调用更多方法(Where, Where.Take, Where.Take.Select)时,普通 LINQ 的分配会增加,而 ZLinq 则保持为零分配。
性能表现取决于数据源、数量、元素类型和方法链。为了确认 ZLinq 在大多数情况下表现更优,我们在 GitHub Actions 上准备了各种基准测试场景:ZLinq/actions/Benchmark。虽然存在 ZLinq 在结构上无法获胜的情况,但在大多数实际场景中它都更胜一筹。
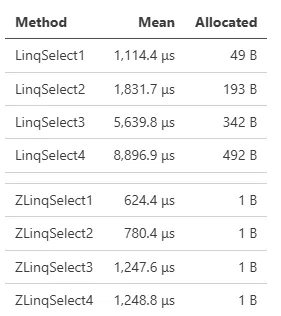
对于基准测试中差异极大的情况,考虑多次调用 Select。System.LINQ 和 ZLinq 在这种情况下都不会应用特殊优化,但 ZLinq 显示出显著的性能优势:
(内存测量 1B 是 BenchmarkDotNet MemoryDiagnoser 的错误。文档明确指出 MemoryDiagnoser 的准确度为 99.5%,这意味着可能会出现轻微的测量误差。)
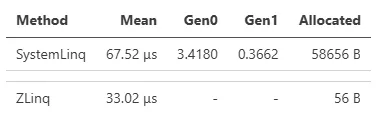
在简单情况下,需要中间缓冲区的操作(如 Distinct 或 OrderBy)显示出巨大差异,因为积极的池化(pooling)显著减少了分配(ZLinq 使用了较为积极的池化,因为它主要基于 ref struct,预期生命周期较短):
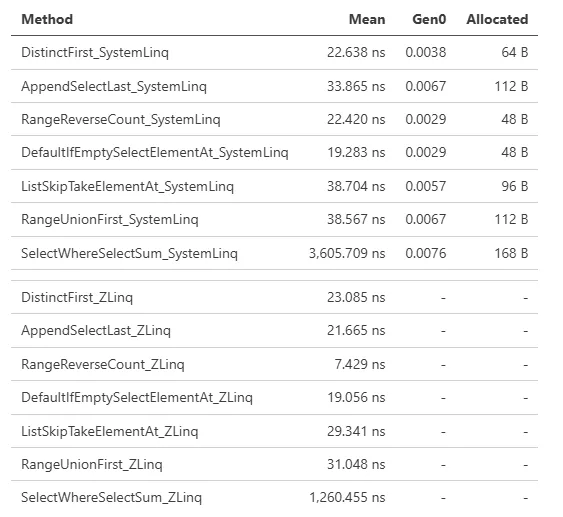
LINQ 会根据方法调用模式应用特殊优化,因此仅减少分配不足以始终超越它。对于操作符链的优化(例如 .NET 9 中引入并在 Performance Improvements in .NET 9 中描述的),ZLinq 实现了所有这些优化以达到更高的性能:
ZLinq 的一大好处是,这些 LINQ 的演进优化对所有 .NET 世代(包括 .NET Framework)都可用,而不仅限于最新版本。
使用非常简单——只需添加一个 AsValueEnumerable() 调用。由于所有操作符 100% 覆盖,替换现有代码没有问题:
using ZLinq;
var seq = source
.AsValueEnumerable() // 只需添加这一行
.Where(x => x % 2 == 0)
.Select(x => x * 3);
foreach (var item in seq) { }
为了确保行为兼容性,ZLinq 移植了 dotnet/runtime 中的 System.Linq.Tests,并在 ZLinq/System.Linq.Tests 持续运行它们。
Total tests: 9000
Passed: 8992
Skipped: 8 (Due to ref struct limitations where identical test code can't be run, etc.)
9000 个测试用例保证了行为兼容性(Skip 的情况是由于 ref struct 限制导致无法运行相同的测试代码等)。
此外,ZLinq 提供了一个用于开箱即用(Drop-In)替换的源代码生成器(Source Generator),可以选择性地消除对 AsValueEnumerable() 的需求:
[assembly: ZLinq.ZLinqDropInAttribute("", ZLinq.DropInGenerateTypes.Everything)]
此机制允许您自由控制开箱即用替换的范围。ZLinq/System.Linq.Tests 本身使用开箱即用替换,在不更改测试代码的情况下使用 ZLinq 运行现有测试。
ValueEnumerable 架构与优化 关于用法,请参考 ReadMe。这里我将深入探讨优化。该架构的区别不仅仅在于简单地实现了惰性序列执行,与其他语言的集合处理库相比,它包含了许多创新。
构成链式操作基础的 ValueEnumerable<T> 定义如下:
public readonly ref struct ValueEnumerable<TEnumerator, T>(TEnumerator enumerator)
where TEnumerator : struct, IValueEnumerator<T>, allows ref struct // allows ref struct 仅在 .NET 9 或更高版本支持
{
public readonly TEnumerator Enumerator = enumerator;
}
public interface IValueEnumerator<T> : IDisposable
{
bool TryGetNext(out T current); // 相当于 MoveNext + Current
// 优化辅助方法
bool TryGetNonEnumeratedCount(out int count);
bool TryGetSpan(out ReadOnlySpan<T> span);
bool TryCopyTo(scoped Span<T> destination, Index offset);
}
基于此,像 Where 这样的操作符链式调用如下:
public static ValueEnumerable<Where<TEnumerator, TSource>, TSource> Where<TEnumerator, TSource>(
this ValueEnumerable<TEnumerator, TSource> source,
Func<TSource, Boolean> predicate)
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
我们选择这种方法而不是使用 IValueEnumerable<T>,因为如果使用类似 (this TEnumerable source) where TEnumerable : struct, IValueEnumerable<TSource> 的定义,TSource 的类型推断会失败。这是由于 C# 语言的限制:类型推断不能从类型参数约束工作(参见 dotnet/csharplang#6930)。如果按那种方式实现,就需要为海量的组合定义实例方法。LinqAF 采用了那种方法,导致了超过 10 万个方法和巨大的程序集大小,这并不理想。
在 ZLinq 中,所有实现都在 IValueEnumerator<T> 中,并且由于所有枚举器(Enumerator)都是结构体,我意识到我们可以简单地复制传递通用的 Enumerator,而不是使用 GetEnumerator(),这样每个 Enumerator 都可以用其独立的状态进行处理。这最终形成了用 ValueEnumerable<TEnumerator, T> 包装 IValueEnumerator<T> 的结构。这样,类型出现在类型声明中而不是约束中,避免了类型推断问题。
TryGetNext
让我们更详细地看看迭代的核心 MoveNext:
// 传统接口
public interface IEnumerator<out T> : IDisposable
{
bool MoveNext();
T Current { get; }
}
// 迭代示例
while (e.MoveNext())
{
var item = e.Current; // 调用 get_Current()
}
// ZLinq 接口
public interface IValueEnumerator<T> : IDisposable
{
bool TryGetNext(out T current);
}
// 迭代示例
while (e.TryGetNext(out var item))
{
}
C# 的 foreach 会展开为 MoveNext() + Current,这带来两个问题。首先,每次迭代需要两次方法调用:MoveNext 和 get_Current。其次,Current 需要持有一个变量。因此,我将它们合并为 bool TryGetNext(out T current)。这使每次迭代的方法调用减少到一次,提高了性能。
这种 bool TryGetNext(out T current) 方法在 Rust 的迭代器中也使用:
pub trait Iterator {
type Item;
// Required method
fn next(&mut self) -> Option<Self::Item>;
}
为了理解变量持有问题,让我们看看 Select 的实现:
// System.Linq 的 Select (简化)
public sealed class LinqSelect<TSource, TResult> : IEnumerator<TResult>
{
IEnumerator<TSource> source;
Func<TSource, TResult> selector;
TResult current = default!; // 需要持有 current 字段
public TResult Current => current;
public bool MoveNext()
{
if (source.MoveNext())
{
current = selector(source.Current); // 设置字段
return true;
}
return false;
}
}
// ZLinq 的 Select
public ref struct ZLinqSelect<TEnumerator, TSource, TResult> : IValueEnumerator<TResult>
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
TEnumerator source;
Func<TSource, TResult> selector;
// 不需要 current 字段!
public bool TryGetNext(out TResult current)
{
if (source.TryGetNext(out var value)) // 直接获取值
{
current = selector(value); // 直接赋值给输出参数
return true;
}
current = default!;
return false;
}
}
IEnumerator<T> 需要一个 current 字段,因为它通过 MoveNext() 推进,并通过 Current 返回值。然而,ZLinq 同时推进并返回值,消除了存储字段的需要。这在 ZLinq 基于结构体的架构中意义重大。由于 ZLinq 采用了每个方法链完全包含前一个结构体(TEnumerator 是一个结构体)的结构,结构体的大小会随着每个方法链而增长。虽然在合理的方法链长度内性能仍可接受,但更小的结构体意味着更低的复制成本和更好的性能。采用 TryGetNext 对于最小化结构体大小至关重要。
TryGetNext 的一个缺点是它不支持协变(covariance)和逆变(contravariance)。然而,我认为迭代器和数组应该完全放弃对协变/逆变的支持。它们与 Span<T> 不兼容,在权衡利弊时,它们已成为过时的概念。例如,数组到 Span 的转换在运行时可能失败而无法在编译时检测:
// 由于泛型变体,Derived[] 可以被 Base[] 接受
Base[] array = new Derived[] { new Derived(), new Derived() };
// 在这种情况下,强制转换为 Span<T> 或使用 AsSpan() 会导致运行时错误!
// System.ArrayTypeMismatchException: Attempted to access an element as a type incompatible with the array.
Span<Base> foo = array;
class Base;
class Derived : Base;
这种行为之所以存在,是因为这些特性是在 Span<T> 之前添加的,但在 Span 被广泛使用的现代 .NET 中,它是有问题的,导致可能引发运行时错误的特性实际上无法使用。
TryGetNonEnumeratedCount / TryGetSpan / TryCopyTo
天真地枚举所有内容并不能最大化性能。例如,当调用 ToArray 时,如果大小不变(例如 array.Select().ToArray()),我们可以使用 new T[count] 创建一个固定长度的数组。System.LINQ 内部使用 Iterator<T> 类型进行此类优化,但由于参数是 IEnumerable<T>,因此总是需要类似 if (source is Iterator<TSource> iterator) 的代码。
由于 ZLinq 从一开始就是为 LINQ 专门设计的,我们已经为这些优化做好了准备。为了避免程序集大小膨胀,我们精心挑选了能提供最大效果的最小定义集,最终确定了这三个方法。
TryGetNonEnumeratedCount(out int count)在原始数据源具有有限数量且没有过滤方法(Where,Distinct等,不过Take和Skip是可计算的)介入时成功。这有益于ToArray以及需要中间缓冲区的操作,如OrderBy和Shuffle。TryGetSpan(out ReadOnlySpan<T> span)在数据源可以作为连续内存访问时,可能带来巨大的性能提升,使得聚合操作可以通过 SIMD 操作或基于Span的循环处理来加速。TryCopyTo(scoped Span<T> destination, Index offset)通过内部迭代器(internal iterators)提升性能。解释外部迭代器(external iterator)与内部迭代器的区别,考虑List<T>同时提供foreach和ForEach:
// 外部迭代器 (external iterator)
foreach (var item in list) { Do(item); }
// 内部迭代器 (internal iterator)
list.ForEach(Do);
它们看起来相似但性能表现不同。分解实现:
// 外部迭代器
List<T>.Enumerator e = list.GetEnumerator();
while (e.MoveNext())
{
var item = e.Current;
Do(item);
}
// 内部迭代器
for (int i = 0; i < list.Count; i++)
{
action(list[i]); // action 委托调用
}
这就变成了委托调用开销(+ 委托创建分配)与迭代器 MoveNext + Current 调用之间的竞争。迭代速度本身在内部迭代器中更快。在某些情况下,委托调用可能更轻量,使得内部迭代器在基准测试中可能具有优势。
当然,这因情况而异,并且由于无法使用 Lambda 捕获和正常的控制流(如 continue, break, await 等),我个人认为不应使用 ForEach,也不应定义自定义扩展方法来模仿它。然而,这种结构差异是存在的。
TryCopyTo(scoped Span<T> destination, Index offset) 通过接受一个 Span 而不是委托,实现了有限的内部迭代。
以 Select 为例,在 Count 可用时调用 ToArray,它会传递一个 Span 进行内部迭代:
public ref struct ZLinqSelect<TEnumerator, TSource, TResult> : IValueEnumerator<TResult>
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
...
public bool TryCopyTo(Span<TResult> destination, Index offset)
{
// 尝试从源获取 Span (如果可能)
if (source.TryGetSpan(out var sourceSpan))
{
// 计算偏移量和长度 (简化)
if (offset.TryGetOffset(sourceSpan.Length, out var start) && destination.Length <= sourceSpan.Length - start)
{
// 内部迭代:内联循环处理
for (var i = 0; i < destination.Length; i++)
{
destination[i] = selector(sourceSpan[start + i]);
}
return true;
}
}
return false; // 回退到外部迭代
}
}
// ------------------
// ToArray 实现 (简化)
if (enumerator.TryGetNonEnumeratedCount(out var count))
{
var array = GC.AllocateUninitializedArray<TSource>(count); // 预分配精确大小数组
// 尝试内部迭代器 (高效复制)
if (enumerator.TryCopyTo(array.AsSpan(), 0))
{
return array;
}
// 否则,使用外部迭代器 (较慢)
var i = 0;
while (enumerator.TryGetNext(out var item))
{
array[i] = item;
i++;
}
return array;
}
因此,虽然 Select 本身无法创建 Span,但如果原始数据源可以,那么作为内部迭代器处理可以加速循环。
TryCopyTo 与常规 CopyTo 的不同之处在于它包含一个 Index offset 参数,并且允许目标(destination)小于源(正常的 .NET CopyTo 如果目标较小会失败)。当目标大小为 1 时,这可以实现 ElementAt 表示:索引 0 成为 First,^1 成为 Last。将 First, Last, ElementAt 直接添加到 IValueEnumerator<T> 会造成类定义冗余(影响程序集大小),但将小目标与 Index 结合允许一个方法覆盖更多优化场景:
public static TSource ElementAt<TEnumerator, TSource>(
this ValueEnumerable<TEnumerator, TSource> source,
Index index)
where TEnumerator : struct, IValueEnumerator<TSource>, allows ref struct
{
using var enumerator = source.Enumerator;
var value = default(TSource)!;
var span = new Span<TSource>(ref value); // 创建大小为 1 的 Span
if (enumerator.TryCopyTo(span, index)) // 尝试复制目标索引处的单个元素
{
return value;
}
// 否则(失败)... 使用更慢的枚举方式查找元素
}
LINQ to Span
在 .NET 9 及更高版本中,ZLinq 允许在 Span<T> 和 ReadOnlySpan<T> 上链式调用所有 LINQ 操作符:
using ZLinq;
// 可以应用于 Span (仅在支持 allows ref struct 的 .NET 9/C# 13 环境中)
Span<int> span = stackalloc int[5] { 1, 2, 3, 4, 5 };
var seq1 = span.AsValueEnumerable().Select(x => x * x);
// 如果启用了 Drop-in 替换,可以直接调用 LINQ 操作符。
var seq2 = span.Select(x => x); // 需要 Drop-in 替换
虽然有些库声称支持 LINQ for Spans,但它们通常只为 Span<T> 定义扩展方法,而没有通用机制。由于之前语言的限制(无法将 Span<T> 作为泛型参数接收),它们只提供有限的操作符。随着 .NET 9 中引入 allows ref struct,泛型处理成为可能。
在 ZLinq 中,IEnumerable<T> 和 Span<T> 没有区别——它们被同等对待。
然而,由于 allows ref struct 需要语言/运行时支持,而 ZLinq 支持从 .NET Standard 2.0 起的所有 .NET 版本,因此对 Span 的支持仅限于 .NET 9 及以上版本。这意味着在 .NET 9+ 中,所有操作符都是 ref struct,这与早期版本不同。
LINQ to SIMD
System.Linq 使用 SIMD 加速某些聚合方法。例如,直接在原始类型数组上调用 Sum 或 Max 比使用 for 循环更快。然而,基于 IEnumerable<T>,适用的类型受到限制。ZLinq 通过 IValueEnumerator.TryGetSpan 使其更通用,目标是那些可以获取 Span<T> 的集合(包括直接应用 Span<T>)。
支持的方法包括:
Range到ToArray/ToList/CopyTo/等…Repeat(对于非托管结构体且大小为 2 的幂)到ToArray/ToList/CopyTo/等...Sum:适用于sbyte,short,int,long,byte,ushort,uint,ulong,doubleSumUnchecked:适用于sbyte,short,int,long,byte,ushort,uint,ulong,doubleAverage:适用于sbyte,short,int,long,byte,ushort,uint,ulong,doubleMax:适用于byte,sbyte,short,ushort,int,uint,long,ulong,nint,nuint,Int128,UInt128Min:适用于byte,sbyte,short,ushort,int,uint,long,ulong,nint,nuint,Int128,UInt128Contains:适用于byte,sbyte,short,ushort,int,uint,long,ulong,bool,char,nint,nuintSequenceEqual:适用于byte,sbyte,short,ushort,int,uint,long,ulong,bool,char,nint,nuint
Sum 会检查溢出,这会增加开销。我们添加了一个更快的自定义 SumUnchecked 方法:
由于这些方法在条件匹配时会隐式应用,因此需要理解内部流水线才能有效利用 SIMD。因此,对于 T[], Span<T>, 或 ReadOnlySpan<T>,我们提供了 .AsVectorizable() 方法来显式调用可应用 SIMD 的操作,如 Sum, SumUnchecked, Average, Max, Min, Contains, 和 SequenceEqual(尽管当 Vector.IsHardwareAccelerated && Vector<T>.IsSupported 为 false 时,这些方法会回退到正常处理)。
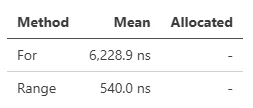
int[] 或 Span<int> 获得了 VectorizedFillRange 方法,它执行与 ValueEnumerable.Range().CopyTo() 相同的操作,使用 SIMD 加速填充顺序数字。在需要时,这比使用 for 循环填充快得多:
可向量化方法(Vectorizable Methods)
手写 SIMD 循环处理需要练习和努力。我们提供了一些接受 Func 参数的辅助方法,以便轻松使用。虽然这些会产生委托开销,性能不如内联代码,但它们便于进行简单的 SIMD 处理。它们接受 Func<Vector<T>, Vector<T>> vectorFunc 和 Func<T, T> func,尽可能使用 Vector<T> 处理,并使用 Func<T> 处理剩余部分。
T[] 和 Span<T> 提供了 VectorizedUpdate 方法:
using ZLinq.Simd; // 需要 using
int[] source = Enumerable.Range(0, 10000).ToArray();
[Benchmark]
public void For()
{
for (int i = 0; i < source.Length; i++)
{
source[i] = source[i] * 10;
}
}
[Benchmark]
public void VectorizedUpdate()
{
// arg1: Vector<int> => Vector<int> (处理向量块)
// arg2: int => int (处理剩余元素)
source.VectorizedUpdate(static x => x * 10, static x => x * 10);
}
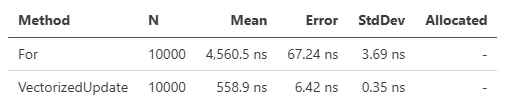
虽然比 for 循环快,但性能因机器环境和大小而异,建议针对每个用例进行验证。
AsVectorizable() 提供了 Aggregate, All, Any, Count, Select, 和 Zip:
// 使用向量和标量函数进行聚合
source.AsVectorizable().Aggregate((x, y) => Vector.Min(x, y), (x, y) => Math.Min(x, y))
// 所有元素是否都满足条件 (向量和标量谓词)
source.AsVectorizable().All(x => Vector.GreaterThanAll(x, new(5000)), x => x > 5000);
// 是否存在元素满足条件 (向量和标量谓词)
source.AsVectorizable().Any(x => Vector.LessThanAll(x, new(5000)), x => x < 5000);
// 计数满足条件的元素 (向量和标量谓词)
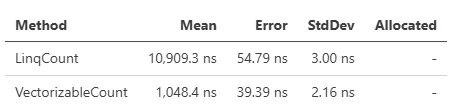
source.AsVectorizable().Count(x => Vector.GreaterThan(x, new(5000)), x => x > 5000);
性能取决于数据,但 Count 可以显示出显著差异:
对于 Select 和 Zip,您需要接着调用 ToArray 或 CopyTo:
// Select
source.AsVectorizable().Select(x => x * 3, x => x * 3).ToArray();
source.AsVectorizable().Select(x => x * 3, x => x * 3).CopyTo(destination);
// Zip2 (合并两个序列)
array1.AsVectorizable().Zip(array2, (x, y) => x + y, (x, y) => x + y).CopyTo(destination);
array1.AsVectorizable().Zip(array2, (x, y) => x + y, (x, y) => x + y).ToArray();
// Zip3 (合并三个序列)
array1.AsVectorizable().Zip(array2, array3, (x, y, z) => x + y + z, (x, y, z) => x + y + z).CopyTo(destination);
array1.AsVectorizable().Zip(array2, array3, (x, y, z) => x + y + z, (x, y, z) => x + y + z).ToArray();
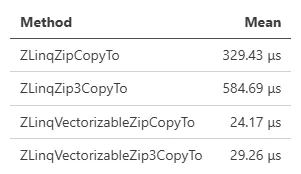
对于某些用例(比如合并两个 Vec3),Zip 可能特别有趣且快速:
LINQ to Tree 您用过 LINQ to XML 吗?在 2008 年 LINQ 出现时,XML 仍占主导地位,LINQ to XML 的易用性令人震惊。现在 JSON 已经占据主导,LINQ to XML 很少使用了。
然而,LINQ to XML 的价值在于它是对树形结构进行 LINQ 风格操作的参考设计——一个使树形结构兼容 LINQ 的指南。树遍历抽象与 LINQ to Objects 配合得非常好。一个典型的例子是处理 Roslyn 的 SyntaxTree,其中像 Descendants 这样的方法在分析器(Analyzers)和源代码生成器(Source Generators)中很常用。
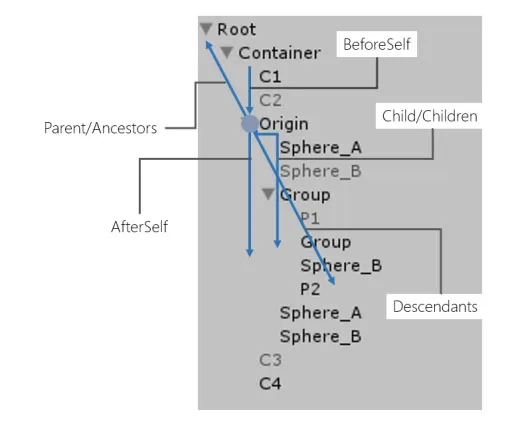
ZLinq 扩展了这一概念,定义了一个接口,该接口为树形结构(如 Unity 的 GameObject)通用地启用了 Ancestors(祖先)、Children(子节点)、Descendants(后代)、BeforeSelf(前兄弟节点)和 AfterSelf(后兄弟节点):
我们已经为文件系统(DirectoryTree)和 JSON(在 System.Text.Json 的 JsonNode 上启用类似 LINQ to XML 的操作)包含了标准实现。当然,您可以为自定义类型实现该接口:
public interface ITraverser<TTraverser, T> : IDisposable
where TTraverser : struct, ITraverser<TTraverser, T> // 自约束 (self)
{
T Origin { get; } // 起始节点
TTraverser ConvertToTraverser(T next); // 用于 Descendants
bool TryGetHasChild(out bool hasChild); // 可选:优化 Descendants 的使用
bool TryGetChildCount(out int count); // 可选:优化 Children 的使用
bool TryGetParent(out T parent); // 用于 Ancestors
bool TryGetNextChild(out T child); // 用于 Children | Descendants
bool TryGetNextSibling(out T next); // 用于 AfterSelf
bool TryGetPreviousSibling(out T previous); // 用于 BeforeSelf
}
对于 JSON,您可以这样写:
var json = JsonNode.Parse("""
{
"nesting": {
"level1": {
"level2": [
[true, false, true],
["fast", "accurate", "balanced"],
[1, 1, 2, 3, 5, 8, 13]
]
}
}
}
""");
// 获取起始节点
var origin = json!["nesting"]!["level1"]!["level2"]!;
// JsonNode 轴操作: Children, Descendants, Ancestors, BeforeSelf, AfterSelf 以及 ***Self.
foreach (var item in origin.Descendants().Select(x => x.Node).OfType<JsonArray>())
{
// 输出: [true, false, true], ["fast", "accurate", "balanced"], [1, 1, 2, 3, 5, 8, 13]
Console.WriteLine(item.ToJsonString(JsonSerializerOptions.Web));
}
我们为 Unity 的 GameObject 和 Transform 以及 Godot 的 Node 包含了标准的 LINQ to Tree 实现。由于分配和遍历性能都经过精心优化,它们甚至可能比手动循环更快。
OSS 与我 近几个月 .NET 相关的 OSS 发生了几起事件,包括知名 OSS 项目的商业化。我在 github/Cysharp 下有超过 40 个 OSS 项目,加上我个人名下的项目和其他组织(如 MessagePack)下的项目,总共拥有超过 50,000 星,我相信我是 .NET 生态系统中最大的 OSS 提供者之一。
关于商业化,我目前没有计划,但由于规模不断扩大,维护变得越来越具有挑战性。OSS 项目不顾批评尝试商业化的一个主要因素是维护者的精神负担(补偿与时间投入不匹配)。我也有同感!
抛开财务方面,我的请求是用户接受偶尔的维护延迟!在开发像 ZLinq 这样的大型库时,我需要专注的时间,这意味着其他库的 Issues 和 PR 可能几个月得不到回应。我故意不去看它们,甚至不读标题(避免看仪表盘和通知邮件)。这种看似疏忽的做法对于创建创新库是必要的——必要的牺牲!
即使没有这种情况,庞大的库数量也意味着轮转延迟几个月是不可避免的。这是由于绝对的人力短缺,所以请接受这些延迟,不要仅仅因为响应慢就说“这个库死了”。这听起来很刺耳!我尽力而为,但创建新库消耗巨大时间,会导致连锁延迟,消耗我的精力。
此外,与微软相关的不愉快也会降低动力——这是 C# OSS 维护者的普遍经历。尽管如此,我希望能长期坚持下去。
结论
ZLinq 的结构在最初预览版发布后根据反馈发生了重大变化。@Akeit0 为核心性能关键元素(如 ValueEnumerable<TEnumerator, T> 的定义和在 TryCopyTo 中添加 Index)提供了许多建议。@filzrev 贡献了大量的测试和基准测试基础设施。没有他们的贡献,确保兼容性和性能改进是不可能的,我深表感谢。
虽然零分配 LINQ 库并不新颖,但 ZLinq 的全面性使其脱颖而出。凭借经验和知识,在纯粹决心的驱动下,我们实现了所有方法,运行了所有测试用例以确保完全兼容,并实施了包括 SIMD 在内的所有优化。这确实充满挑战!
时机也很完美,因为 .NET 9/C# 13 提供了完整实现所需的所有语言特性。同时,保持对 Unity 和 .NET Standard 2.0 的支持也很重要。
除了作为一个零分配 LINQ 库之外,LINQ to Tree 是我最喜欢的特性,希望大家能尝试一下!
LINQ 的一个性能瓶颈是委托,一些库采用 ValueDelegate 方法(使用结构体模拟 Func)。我们特意避开了这一点,因为这样的定义由于其复杂性而不实用。使用 ValueDelegate 结构体写 LINQ 不如直接写内联代码。为了基准测试技巧而使内部结构复杂化和膨胀程序集大小是浪费的,因此我们只接受与 System.Linq 兼容的方式。
R3 是一个旨在取代 .NET 标准 System.Reactive 的雄心勃勃的库,但取代 System.Linq 将是一个更大甚至可能过度的任务,因此我认为可能会有一些采用阻力。然而,我相信我们已经展示了足够的优势来证明替换的合理性,如果您能尝试一下,我将非常高兴!