如何使用 Python 语言和 Laravel 框架创建自己的搜索引擎 - 第 1 步(共 4 步)
作者:微信公众号:【架构师老卢】
8-9 8:4
1344

第 1 步:通用搜索引擎应用程序架构
什么是搜索引擎?
搜索引擎基本上是旨在搜索数据库中与用户给定的查询匹配的项目的程序。
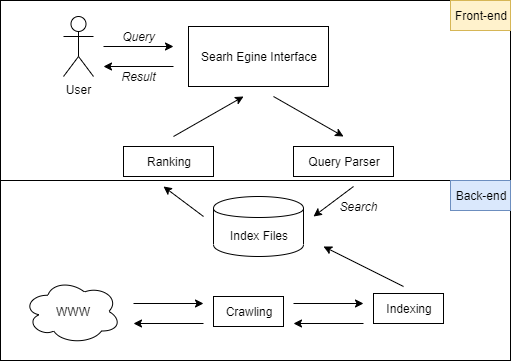
搜索引擎应用程序的图表结构
在上面的图表结构中,可以看到搜索引擎应用程序有后端和前端两个侧面。
后端收集数据集并索引数据集,而前端端管理搜索引擎接口并向后端提供查询以进行排名
后端
爬虫通常是指处理大型数据集,您可以在其中开发自己的爬虫(或机器人),这些爬虫可以爬到网页的最深处。
索引被定义为一种数据结构技术,它允许您从数据库文件中快速检索记录
前端
查询是指用户用来从数据集中查找用户所需的数据的关键字。在索引过程中,每个数据集对每个单词查询都有一个分数,这个分数计算的结果将决定每个数据集的排名
建立
我们将在以下环境中开发它:
- Python 3.x.x
我们将使用 python 语言作为后端编程 - Scrapy 1.8.0
Scrapy 将用于从另一个网页收集数据集,并将它们变成我们的数据集 - Laravel 6.0
这个基于 Web 的搜索引擎应用程序将使用 Laravel 作为其框架
安装要求
- 安装 Python 和 Scrapy
您可以在官网 python.org 下载最新的python。
通过键入以下命令检查已安装的 Python 3 版本:
python3 -V//Output
Python 3.7.2
要管理 Python 的软件包,请安装 pip,该工具将安装和管理要在项目中使用的库或模块。
sudo apt install -y python3-pip
可以通过键入以下命令来安装 Python 包:
pip install package_name
在这里,可以引用任何 Python 包或库。因此,如果您想安装 Scrapy,可以使用以下命令进行安装。
2. 安装 Laravel 框架
Laravel 利用 Composer 来管理其依赖项。因此,在使用 Laravel 之前,请确保您的计算机上安装了 Composer。
您可以通过在终端中发出 Composer 命令来安装 Laravel:create-project
composer create-project --prefer-dist laravel/laravel SearchEngine
继续下一部分!
我希望您发现本教程的第一部分对您有所帮助。我们了解了什么是搜索引擎以及它是如何工作的。
在下一部分中,我们将使用 Python Scrapy 从另一个网页收集数据集,并使我们的搜索引擎正常工作!
源代码获取:公众号回复消息【code:38113】
相关代码下载地址

重要提示!:取消关注公众号后将无法再启用回复功能,不支持解封!
第一步:微信扫码关键公众号“架构师老卢”
第二步:在公众号聊天框发送code:38113,如: code:38113 获取下载地址
code:38113 获取下载地址
code:38113 获取下载地址
第三步:恭喜你,快去下载你想要的资源吧
相关留言评论
昵称:
邮箱:
阅读排行
11605
5307
4040
3907
2100
2086
1775
2798
1578
1569
1674
1437
1536
1638
1524
1422
1499
1375
1492
1497
1297
1291