为什么选择 ETL-Zero?了解数据集成的转变

在我备考Salesforce数据云认证时,遇到了“零ETL”这个术语。数据云提供了直接从其他系统(如数据仓库或数据湖)访问数据的可能性,也能在不复制数据的情况下与这些系统共享数据。Salesforce也将其描述为“自带数据湖(BYOL)”,参考了“自带设备(BYOD)”这个术语。我想更好地理解零ETL的概念,并以一种易于理解的方式对其进行阐释。
在本文中,我将向你展示如何使用Python创建一个简化的ETL流程,以便更好地理解这个概念,弄清楚零ETL或零拷贝的含义,以及这种新的数据集成方法是如何在Salesforce数据云中实现的。
目录
传统ETL流程:面向初学者的Python分步指南
那么,什么是零ETL?
为何采用零ETL?其优势与劣势
在Salesforce数据云中零ETL是什么样的?
总结思考
传统ETL流程:面向初学者的Python分步指南 如果你已经熟悉ETL和ELT流程,可以跳过本部分。如果你刚接触这个主题,看看这个超级简化的示例,以便更好地理解抽取(Extract)、转换(Transform)、加载(Load)这个流程。或者更好的做法是自己动手构建一下——通过实践,你通常能更好地理解这些概念。
1 - 抽取(Extract) 在传统的ETL数据处理管道中,数据是从诸如数据库、API、JSON文件、XML文件或其他数据仓库等数据源收集而来的。
在我们的示例中,首先要创建一个包含客户数据的CSV文件。我已经整理好了一个包含示例数据的文件,其中有“名字(First Name)”“姓氏(Last Name)”“电子邮件(Email)”“已购产品(Purchased _Product)”和“支付价格(Price_Paid)”这些列。你可以在GitHub上找到CSV文件以及代码。
然后我们使用pandas读取这个CSV文件,并显示前5行:
import pandas as pd
import sqlite3
import matplotlib.pyplot as plt
# 步骤1:抽取
# 从csv文件读取数据
file_path = 'YOURPATH' # 在Windows系统中,路径需用/分隔
data = pd.read_csv(file_path)
print("抽取的数据:")
print(data.head())

这些数据展示了从包含客户数据的CSV文件中抽取的数据。
如果你在搭建Python环境方面需要帮助,最好阅读一下《Python数据分析生态系统——初学者路线图》一文中的步骤。我在做这类项目时会使用Anaconda和Jupyter Lab。要使代码正常运行,你需要安装pandas、sqlite3和matplotlib。如果你使用的是Anaconda,可以在Anaconda命令提示符终端中输入命令“conda install pandas, sqlite, matplotlib”。
2 - 转换(Transform) 在传统ETL流程中,一旦数据被抽取出来,紧接着就是数据转换环节。这可能意味着列值要进行合并、执行计算、合并表格或者移除不必要的信息。
在我们的示例中,这一步将进行两项简单的转换。首先,我们基于名字和姓氏创建一个新列来存储全名。然后,在一个新列中,我们要区分出消费金额高的客户和消费金额低的客户。为此,我们还要创建一个新的布尔型列,对于支付金额超过20的所有行填入“是(Yes)”。
# 步骤2:转换
# 通过组合名字和姓氏创建新列“全名(Full_Name)”
data['Full Name'] = data['First Name'] + ' ' + data['Last Name']
# 如果“支付价格(Price_Paid)”大于20,则在新列“高消费(High_Payment)”中填入“是(Yes)”,否则填入“否(No)”
data['High_Payment'] = data['Price_Paid'].apply(lambda x: 'Yes' if x > 20 else 'No')
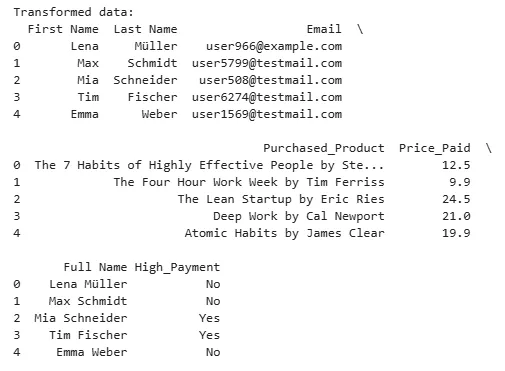
我们再次显示前5行,以检查这些转换是否成功完成(新增了“全名(Full Name)”和“高消费(High_Payment)”这两个新列):
# 显示前5行
print("转换后的数据:")
print(data.head())
3 - 加载(Load) 转换之后,传统ETL流程涉及将数据加载到一个平台上以便进行进一步分析。例如,可以对数据应用机器学习方法,或者将数据可视化用于仪表盘和报告。
在我们的示例中,这一步将把转换后的数据加载到一个SQLite数据库中。可以说,SQLite是MySQL的“妹妹”,它非常适合处理中小型数据量的简单项目。在这里,我们还会对数据进行一个小分析并将其可视化。
# 步骤3:加载
# 连接到SQLite数据库(如果不存在则创建它)
conn = sqlite3.connect('output_database.db')
# 将数据框加载到SQLite数据库中的一个新表
data.to_sql('transformed_data', conn, if_exists='replace', index=False)
# 分析:确定有多少客户进行了高额支付
high_payment_count = data[data['High_Payment'] == 'Yes'].count()
print("高额支付的数量:", high_payment_count['High_Payment'])
# 关闭数据库连接
conn.close()
print("ETL流程已完成。转换后的数据已保存到‘output_database.db’中。")
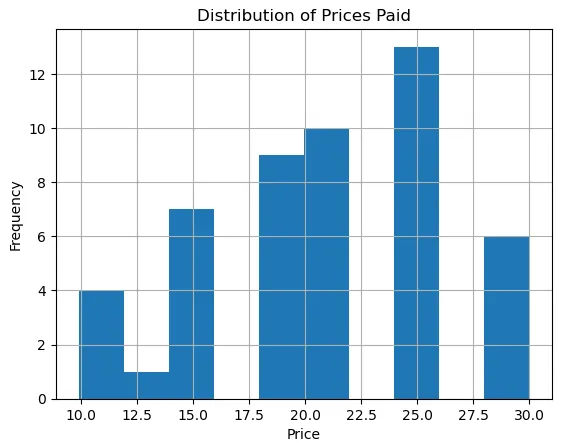
# 可视化数据
data['Price_Paid'].hist(bins=10)
plt.title('支付价格分布')
plt.xlabel('价格')
plt.ylabel('频率')
plt.show()
如你所见,这个示例非常简化。当然,在实际项目中抽取的数据量要大得多,转换操作通常也复杂得多,而且数据通常会被加载到其他数据库、数据仓库、数据湖或数据可视化工具等系统中。
那么,这种传统ETL流程存在哪些挑战呢?
通过这个流程,数据无法实时获取,通常是按批次进行处理和复制的。此外,该流程需要更多资源,因此会消耗更多成本。这就是零ETL概念产生的背景。
- 那么,什么是零ETL? 我们生活在一个即时的时代。每条消息、每部电影、每首歌曲都必须能随时立即获取——当然,这要归功于WhatsApp、Netflix和Spotify等的成功,这里仅举几个例子。
这正是亚马逊网络服务(Amazon Web Services)、谷歌云(Google Cloud)和微软Azure等云服务提供商所秉持的理念:数据应该能够几乎实时地进行处理和分析,且没有较大延迟。
零ETL是数据集成领域的一个概念。与传统上需要在不同步骤中明确地抽取、转换和加载数据不同,数据应该能在不同系统之间无缝流动。这个术语是亚马逊网络服务(AWS)在2022年为将亚马逊Aurora集成到亚马逊Redshift中而引入的。
这个概念的新颖之处在于,该技术使得能够以原始格式几乎实时地使用或分析数据。无需移动数据,数据延迟被最小化,数据可以在单个平台内进行转换和分析。
想象一下,传统ETL就好比在屋外用水桶收集水,然后再把水提到淋浴间。这个过程不仅耗时费力,而且在路上还可能会洒水。好吧,10年前我在坦桑尼亚待了4个月,当时我就是这么洗澡的;)但正常情况下,你大概率会更喜欢像零ETL运输水那样的淋浴方式:换个角度说,零ETL意味着你站在淋浴间,打开水龙头,干净的水就直接流出来了。水(或者说数据)无需被搬运到别的地方,即便它存储在不同位置,也能直接使用。
如果你想进一步了解使零ETL成为可能的技术,我推荐阅读DataCamp的一篇博客文章。那里对数据库复制、联邦查询、数据流以及就地数据分析等术语都有很好的解释。
零ETL并不遵循抽取 - 转换 - 加载的流程。借助零ETL,云平台能够近乎实时地访问和共享数据。
自己绘制的示意图

- 为何采用零ETL?其优势与劣势 企业希望尽量缩短数据可用于分析和进一步处理(例如在营销或销售方面)所需的时间。零ETL或零拷贝使系统能够同时从多个不同的数据库访问数据。对于机器学习功能来说,获取当前数据对于精确训练模型和实现相关预测尤为重要,或者至少是非常有帮助的。
优势
- 无需数据复制:数据无需从一个系统物理复制到另一个系统。
- 能够使用实时数据:具体来说这意味着什么呢?例如,在数据湖仓(Data Lakehouse)中,过去24小时内购物车放弃情况的数据可以直接在营销自动化工具中使用,以便向这些客户发送个性化优惠。这无疑是一个优势,在电子商务等快速发展的行业中尤其如此。
- 错误更少:由于数据不再进行复制或转换,这一步骤出现错误的风险更低。系统直接访问目标系统中的数据,而且数据仍保留在目标系统内。
劣势
- 网络连接可能导致问题:如果连接出现故障、不稳定或者速度慢,就可能会产生延迟。这时,系统中有数据副本会更方便些。
- 数据管理的复杂性:跨多个系统(可能还涉及多个部门)管理数据可能会更困难。
- 对云解决方案的依赖:许多公司,尤其是中型企业,未必在其架构中实施了云技术。对于这类公司来说,集成零ETL可能需要付出相对较大的努力。
- 在Salesforce数据云中零ETL是什么样的? 数据云是Salesforce提供的一个客户数据平台(CDP),它集成了零ETL概念。这意味着数据云能够访问存储在不同数据库中的数据,而无需移动、复制或重新格式化这些数据。反过来,像Snowflake或Google BigQuery这样的数据仓库也可以查看并使用来自数据云的数据。
在数据仓库中使用数据云的数据 想象一下,一家电子公司将其所有潜在客户和联系人数据都存储在Salesforce客户关系管理系统(CRM)中。这个CRM与数据云相连接,以便数据随后能在营销工具中使用。该公司将在线行为、客户服务交互以及物流方面的数据存储在数据云中。例如,它还使用“计算洞察(Calculated Insights)”来计算客户终身价值(CLV)。该公司还使用像Snowflake这样的数据仓库,在其中存储网站上所有已售产品的交易数据、所售产品的相关信息以及交付和库存水平的数据。
现在,该公司无需从数据云物理复制数据,而是可以在Snowflake中创建一个虚拟表,该虚拟表直接指向Salesforce数据云中的数据。这意味着公司可以直接在Snowflake中对这些数据进行查询,即便数据仍保留在数据云中。
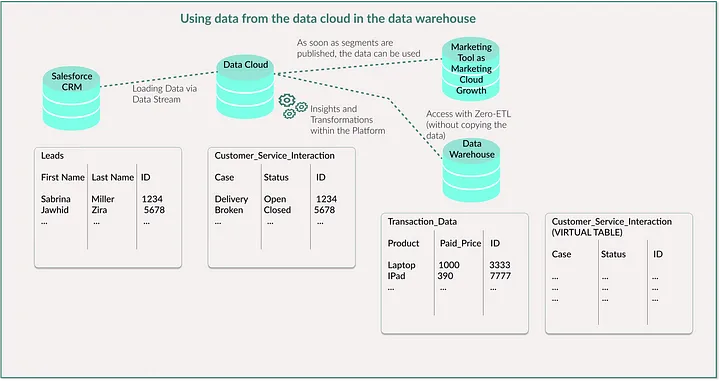
在数据仓库中使用数据云的数据 自己绘制的示意图
如何做到这一点呢? 在数据云中,首先必须定义数据湖对象、数据模型对象或计算洞察。然后设置数据共享。这意味着,你必须将这些对象链接到数据共享目标——在我们的示例中就是Snowflake。在Snowflake中,你需要创建包含结构以及指向数据云中实际数据的引用的虚拟表。然后你就可以在Snowflake中对这些虚拟表运行查询,就好像数据是本地存储的一样。
在数据云中使用数据仓库的数据 为了说明反过来的情况,想象一家销售家用电器产品的公司。该数据仓库存储了所有在线或实体店购买记录、产品系列中所有产品的信息以及物流链的数据。该公司使用数据云来利用Snowflake中的数据以及关联的客户关系管理系统(CRM)进行营销产品,并利用这些数据更大程度地实现营销活动的个性化。
如何做到这一点呢? 在数据云中,首先必须建立与Snowflake的连接。这里就涉及到“挂载(mounting)”这个术语。数据云可以将表挂载为外部数据对象。简单来说,这意味着数据云创建了一个指向这些数据的虚拟链接。一旦数据在数据云中作为外部对象可用,你就可以继续使用它,就好像你是通过数据流(将数据加载到数据云的常规方式)获取它的一样。
这无疑能让公司提高效率、降低成本并实时获取最新数据。然而,要对各个系统中数据源的管理情况保持清晰的了解可能会更困难。例如,我会思考哪些用户应该有哪些权限,以及应该能够访问哪些数据。也有可能出现这样的情况:如果网络连接出现故障,或者需要通过多个数据源进行复杂的查询请求,就会产生延迟。

- 思考 ETL、ELT、ETLT还是零ETL:我们可以讨论一下,例如,企业是否有必要更快地获取个人的所有数据,以便能够发送更个性化、更新颖的营销邮件。但先不管这个社会学层面的结论,企业都希望能够尽可能少延迟地从不同系统访问其数据。零ETL技术使云解决方案中实现这一点成为可能,至少在当前给企业带来了竞争优势。